[MLOps] ML모델 서빙하기 (Model Serving in MLOps)
in Programming on MLOps
💡 ML model을 ‘잘’ 서빙하기 위해 어떤 최적화 전략들이 있는지, 그리고 어떤 프레임워크들이 어떤 전략을 사용하는지 알아보자
1. Model Serving 이란?
ML 모델을 production환경에 배포하여 end user나 다른 시스템에서 inference할 수 있도록 하는 프로세스를 model serving이라고 한다.
훈련된 모델을 배포 가능한 형식으로 패키징하고 요청을 위한 API 혹은 기타 endpoint를 설정하여 모델이 production환경에서 확장 가능하고 최적으로 inference를 수행할 수 있도록 하는 작업을 포함한다.
2. Optimization
비교적 무거운 ML 모델을 환경에 올려서 사용해야하고, 비교적 비싼 리소스인 GPU(혹은 TPU) 환경에서 서빙해야하는 등 ML model serving의 특성 상 일반적인 서비스 환경과는 다른 최적화 전략들이 필요함.
Concurrent Model Execution
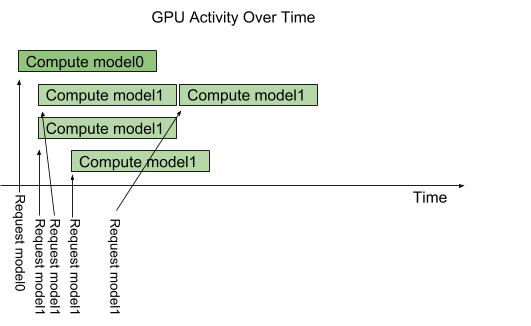
- 여러 모델 or 한 모델을 여러 인스턴스로 띄웠을때 한 시스템에서 병렬로 실행하는 기능
- 여러 요청이 동시에 들어오면, 요청들을 GPU 스케쥴러가 지정된 갯수만큼 병렬로 수행
- ex.) model1은 3개까지 병렬로 처리될수있게 설정함. 4번째 요청은 3개중 하나라도 완료될때까지 대기하게됨
Dynamic Batching (Adaptive Batching)
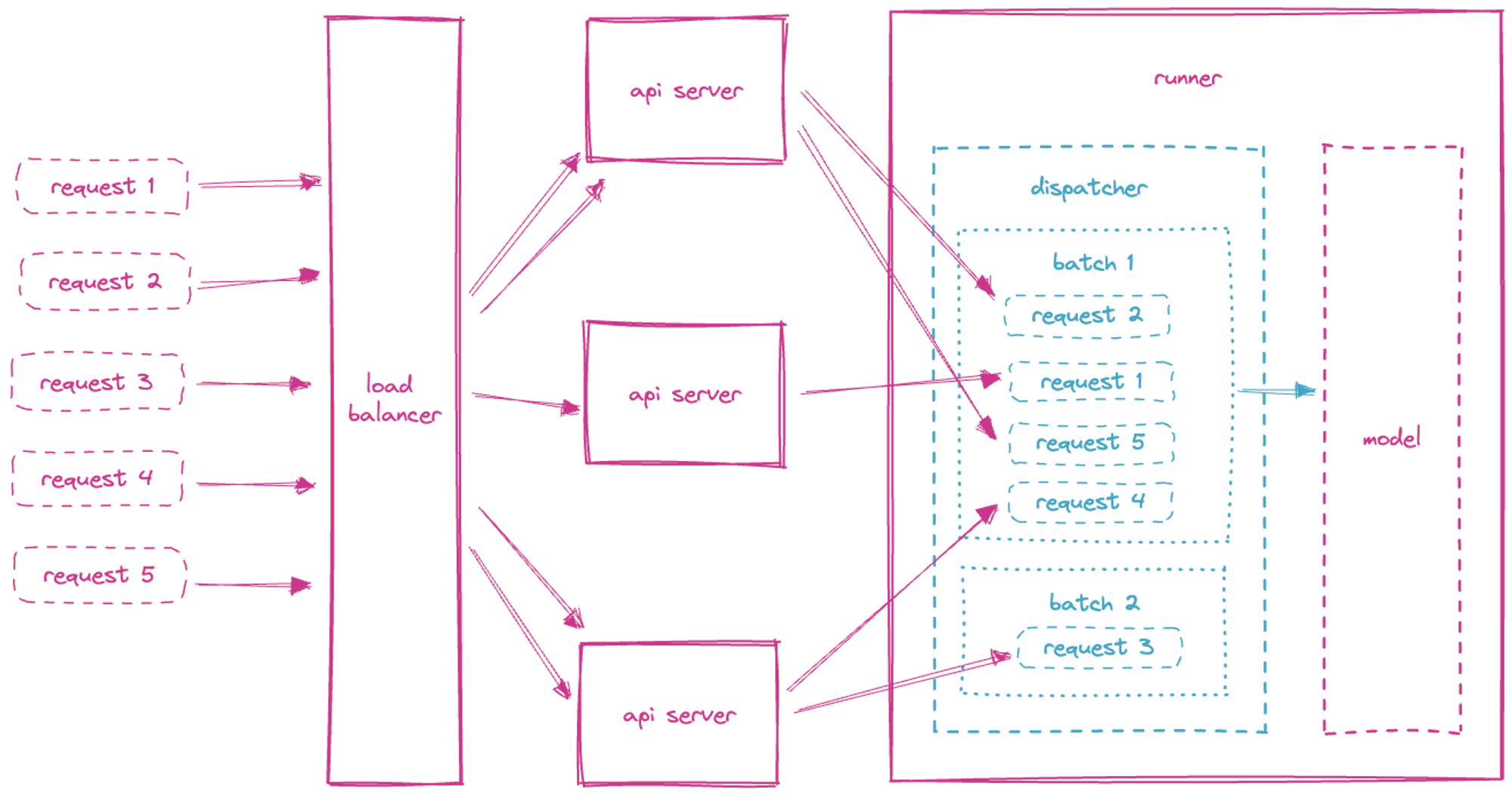
- ML모델을 서빙하는 동안 개별 모델 추론 요청을 모아서 한번에 처리하는것이 성능에 좋음
- GPU같은 하드웨어 가속기가 제공하는 높은 처리량을 활용하려면 일괄처리하는것이 이득임
- 사용자들의 request를 묶어서 inference 한 뒤, 다시 response할때 쪼개서 응답할수있음
- batch size 와 latency 의 trade off.
- utilization, throughput은 최대한 늘리면서도
- 사용자가 용인 가능한 latency로 설정해야..
Model Framework specific optimization
- 기존 모델들을 경량화 or 가속화 or 최적화하는 model framework들이 존재.
- onnx
- tensorRT
- serving framework가 이런 최적화 모델을 지원해주는지 여부 역시 중요하게 고려할 요소 중 하나.
Autoscaling
- GPU는 매우 비싼 리소스
- 사용하지 않을때는 할당 리소스를 줄이고, 사용량이 많을때는 할당 리소스를 늘릴 수 있다면(=Autoscaling) 인프라 비용을 크게 절감할수있음
- 주의) 사용량 등 metric을 계속 추적해야함
- Scale To Zero : 사용하지 않을때는 꺼두는기능.
- 된다면 정말 좋지만… start비용을 어떻게 해결할지가 관건
- 기본적으로 k8s에서 서빙한다면 k8s의 기능들을 사용할수있음
3. Model Serving Framework
고려해야할점들
- 얼마나 쉬운데?
- 얼마나 알아서 잘 최적화해주는데?
- 얼마나 많이 지원하는데?
- 얼마나 안정적인데?
FastAPI
- 그냥 기본 python backend framework.
- 그리고 async 기능을 곁들인..
- 알던지식 쓰면 된다는게 장점
- ‘백엔드’의관점에서 안정성 좋다
- 모든 모델을 그냥 올려서 쓸 수 있음
- 하지만 알아서 최적화해주는건 없다..
- 최적화 로직은 내가 개발해서 쓰는걸로..
Tenserflow Serving
TorchServe
- 근본 frameowrk
- 지원모델 : pytorch, onnx, tensorRT, transformer ..
- mlflow, kubeflow, sagemaker 등 타 프레임워크에서 pytorch를 서빙하기위해 이녀석을 차용
- 배치기능 지원
- 여러 worker를 띄워서, 여러모델 동시수행 가능
NVIDIA Triton
- made by nvidia → 좀더 gpu친화적으로 동작하지않을까 기대해볼수있다
- 지원모델 : tensorRT, onnx, pytorch, transformer, tensorflow, sklearn .. 대부분 다 지원
- dynamic batching 지원
- concurrent model execution 지원
BentoML
- 익숙하고 쉬운문법
- k8s에도 친화적 (yatai?)
- adaptive batching 지원
- runner를 통한 concurrent execution 지원
- 지원모델 : onnx, pytorch, transformer, tensorflow, sklearn .. 대부분 다 지원
- 근데 안정성이 아직…. (v1 ..)
KServe
- (구) KFServing
- kubeflow에 내장되어있었음
- knaive로 autoscaling지원 (scale to zero까지 지원한다고함)
- request batching 지원
- model mesh라는 기능으로 multi model 지원.
- triton server, torchserve 등 기존 서빙프레임웍을 한번 래핑한 형태로 지원
4. Performance
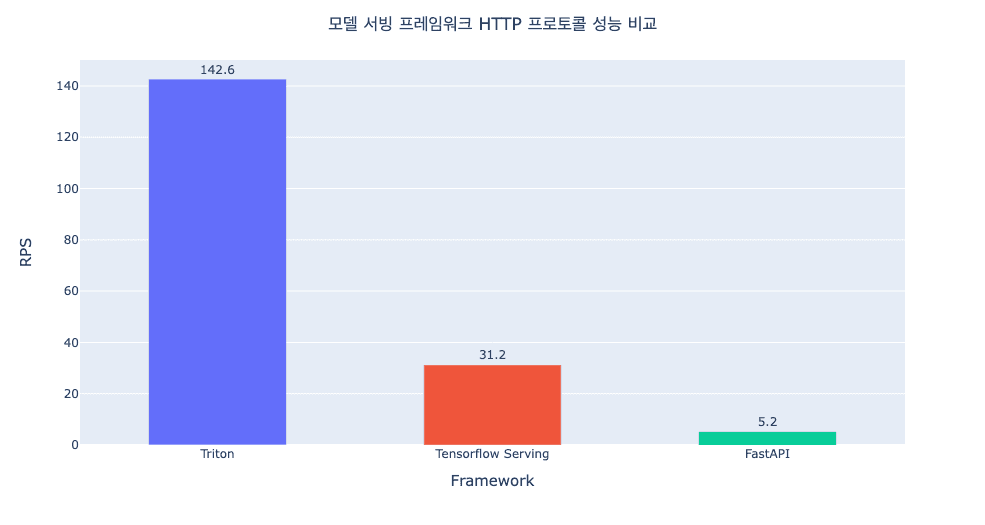
resnet 모델 기준 Triton Inference Server는 Tensorflow Serving, FastAPI와 비교했을 때 더 나은 성능을 보이는 것으로 나타남
5. Summary
| framework | concurrency | batching | support opt model | autoscaling |
|---|---|---|---|---|
| FastAPI | O | X | O | X |
| TensorflowServing | O | O | X | X |
| TorchServe | O | O | O | X |
| Triton | O | O | O | X |
| bentoML | O | O | O | X |
| KServe | O | O | O | O |
이건 KServe 발표영상에서 나왔던 각 프레임웍별 지원모델

https://github.com/triton-inference-server/server/blob/main/docs/user_guide/optimization.md https://github.com/triton-inference-server/server/blob/main/docs/user_guide/architecture.md https://docs.bentoml.org/en/latest/concepts/runner.html
