BERT 톺아보기
in Data Science on Deep Learning
💡 BERT의 출연배경과 동작방법을 알아봅시다
1. 복습을해보자..
1) RNN
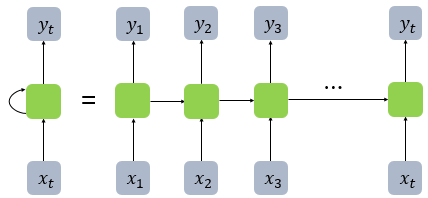
기존의 정보를 활용해서 현재의 출력값을 더 정확히 뽑겠다!
2) Attention
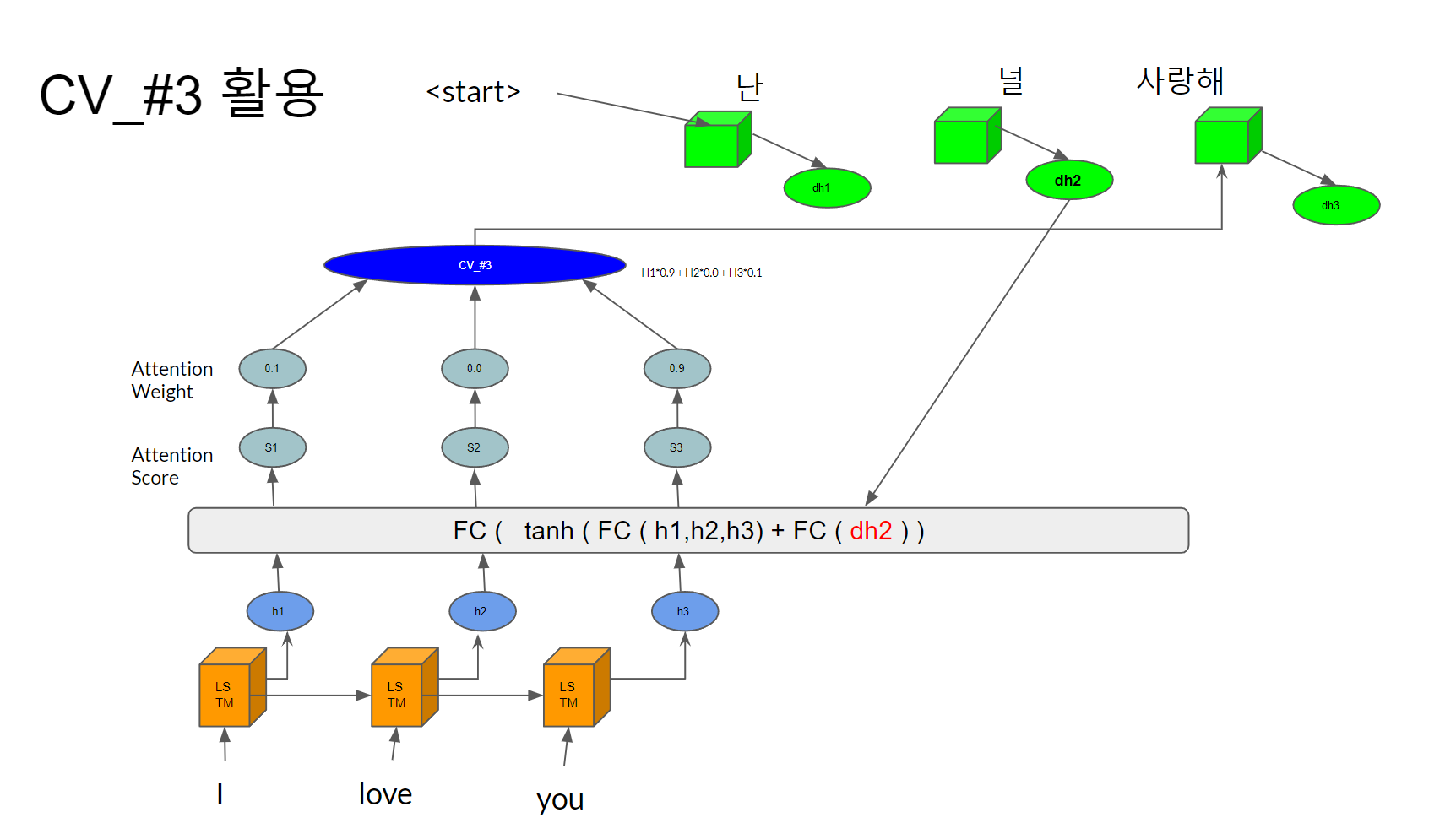
모든 입력값의 hidden state를 활용해보자! 대신, 출력값마다 연관있는놈만 집중해서 봐서 출력값을 더 정확히 뽑겠다!
3) Transformer

attention에서 굳이 RNN이 필요할까..? RNN을 빼버리자! 대신 해당 입력값의 위치정보를 같이 넣어주면되겠지! 속도가 더 빨라졌군.
2. BERT를 위한 빌드업
1) WordPiece Tokenizing

→ subword information을 잘 캐치함
→ OOV 에도 유연한 대응
2) Self-Attention
내가 필요한건 ‘영어’를 잘 이해하는 ‘언어모델’!
영어의 의미를 정교하게 반영한 ‘벡터’를 뽑아낼수있는 모델을 원해.

→ it 이라는 놈은 ‘animal’과 연관이 무척 깊구만
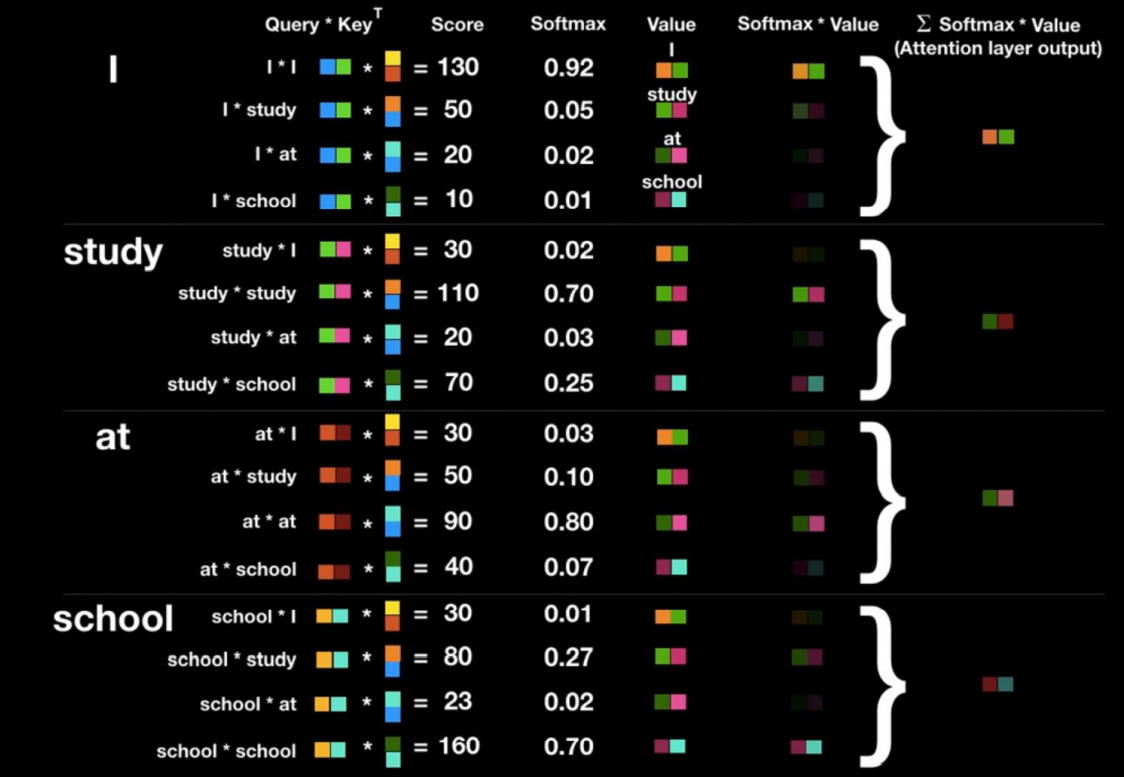
→ 입력 문장에서, 한 단어가 각 단어들과 어떤 연관을 가지는지를 벡터로 표현
→ 이것이 해당 ‘영어’를 잘 표현하는 context vector가 된다!
3) multi-head attention
여러개의 어텐션을 병렬로 처리한 뒤, 합침 → 한 단어에 대한 여러관점의 학습을 합침 → 놓치는 부분 없이 정확한 context벡터를 얻게됨
4) transformer
좋아, 그렇다면 multi-head attention을 사용하고 rnn을 제외하자. 그런데 생각해보니 decoder는 필요가없네? decoder를 빼자.
→ 최종 이 형태의 transformer를 bert에서 사용하게된다
3. BERT
이제 드디어 BERT에 대해서 알아보자


BERT(Bidirectional Encoder Representations from Transformers)
이전 SOTA인 ELMo(Embeddings from Language Model) 라는모델을 겨냥한.. 끼워맞추기
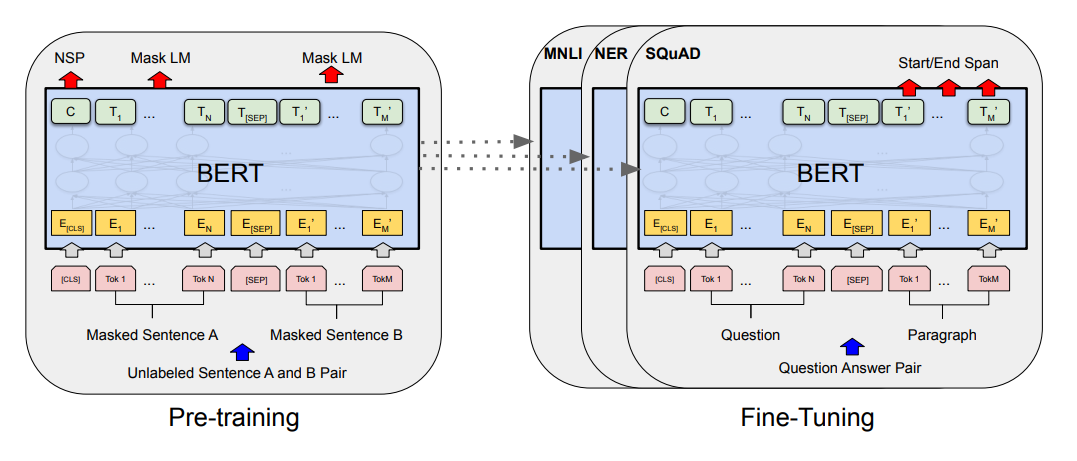
1) Pre-training

언어를 컴퓨터가 잘! 이해하기위한과정.
엄청대용량 corpus를 input으로 넣어서 학습하게됨.
대규모의 context vector 집단. 컴퓨터가 이해할수있는 해당 언어의 숫자집단을 만들기 위한 과정.
모델은 [CLS] 문장1 [SEP] 문장2 형태의 input을 받아 두가지 시험을 치루게됨
- 문장1, 문장2가 이어지는 문장이냐? 를 맞추는 시험
- 문장사이사이 빵꾸(mask)뚫어놓고 거기에 뭐들어가야되냐?를 맞추는 시험
1, 2번 시험을 보면서, 틀리고 오차를 줄이는 과정을 반복하면서 모델은 점점 해당 언어를 정교하게 이해하고 자신들의 언어(vector)로 표현하게됨
[CLS] 에 해당하는 output 벡터는 classification을 위한 벡터로 활용됨. 다른 fine tuning을 위한 작업에서도 유용하게활용됨
2) Fine-tuning
저렇게 pretrained된 언어모델은 그냥 간단한 classification layer 한층만 갖다붙여도! 매우 정확한 결과를 얻을수있다. 이거 한층 갖다 붙이는걸 fine-tuning이라고한다.
논문에서 굉장히 다양한 fine-tuning예시를 알려줌.
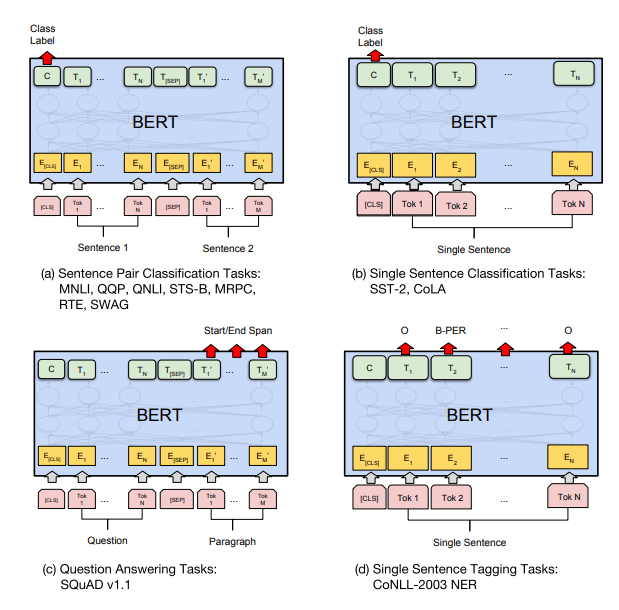

4. 예제
(a) Sentence Pair Classification Task : 장소명 동일여부판단
(c) Question Answering Task : 리뷰에서 부가정보 뽑기
