show and tell
in Data Science on Paper
Show and Tell: A Neural Image Caption Generator
구글에서 2015 CVPR에서 발표한 논문. 말그대로 SHOW AND TELL(그림을 보고 뭔그림인지 말함).
Image Captioning에 대한 논문이다.
그림을 CNN에 넣어서 벡터화한다음에 그걸 RNN에 넣어서 decoding해서 caption을 생성함.
Author
Oriol Vinyals
Google
vinyals@google.com
Alexander Toshev
Google
toshev@google.com
Samy Bengio
Google
bengio@google.com
Dumitru Erhan
Google
dumitru@google.com
Introduction
Idea
Main inspiration – Machine Translation – Task is transform sentence S written in source language into its translation T by maximizing p(T|S)
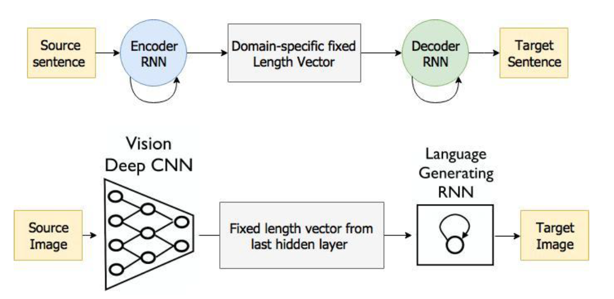
기본적으로 구글 사람들은 이 문제에 접근할 때, 번역기를 생각하고 시작했다. Sequence to sequence 모델에서 encoder RNN이 입력 문장을 vector space로 embeding하여 mapping을 하면 그걸 입력으로 하여 2번째 RNN(decoder RNN)이 embedding vector로부터 추가하여 새로운 문장을 생성하는게 번역기인데, 이 논문 저자들은 캡션 문제에 대해 앞단의 인코딩 rnn을 인코딩cnn으로 바꾸면 이미지를 문장으로 바꿀수있지 않겠냐 라는 아이디어로 시작했다. 간단한 아이디어지지만 당근 말이 되는 아이디어이다.
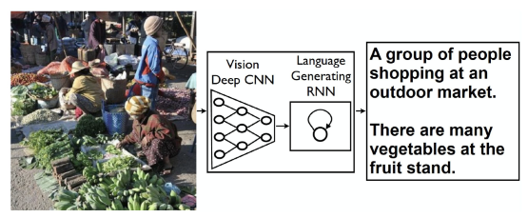
- CNN을 Language RNN과 결합
- Deep CNN을 인코더로 사용
- Language Generating RNN을 decoder로 사용
- End to end model 인데 Image를 문장으로 번역
- 주어진 이미지에 대해서 log likelihood를 maximize하는 단어 시컨스를 찾는게 최종목표
Model
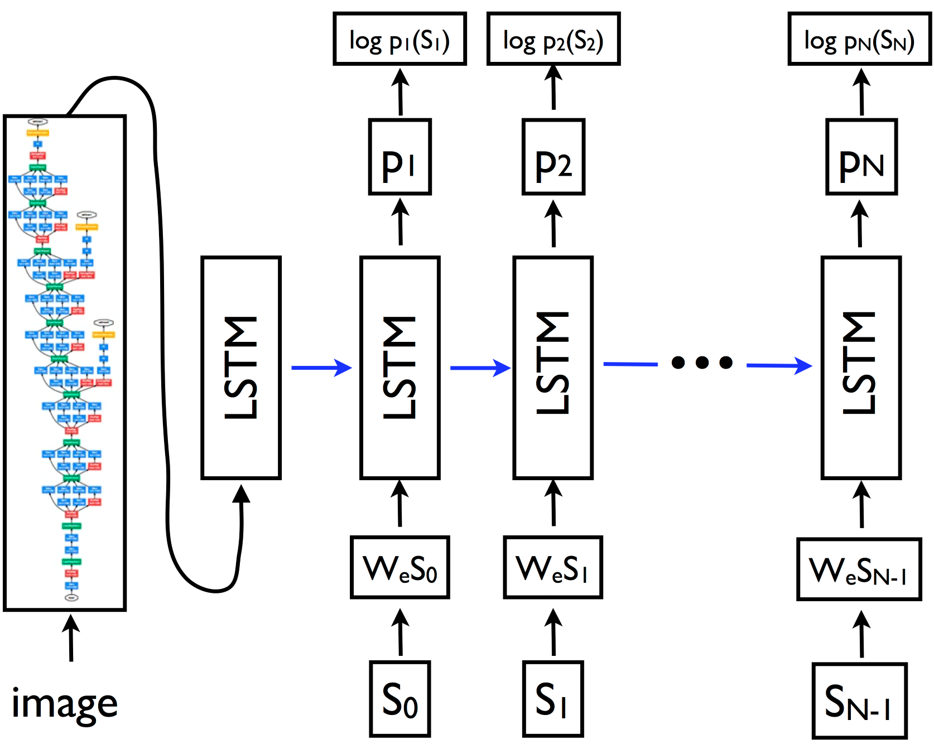
모델은 앞에 CNN 이 있고, 이미지에서 특징을 추출하여 이미지 스페이스 벡터를 만든다. 이걸 word space로 embedding하는 레이어가 하나 있다. word space에 embedding 된 벡터를 LSTM에 입력하여 문장을 생성한다. 이 연구에서는 이미지를 처리하는 CNN부분에는 googlenet을 거의 그대로 사용 했고 이후 버전에서는 Inception V3를 사용한다.
BeamSearch
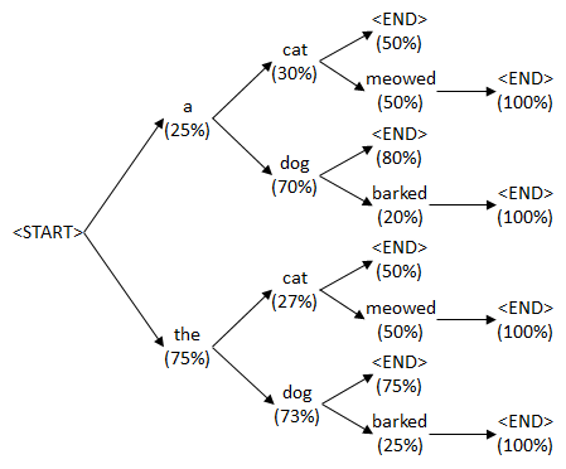
여기 약간 특이한 점은, sentence를 generation 할 때 흔히 sampling을 한다. 어떤 단어가 나오면 word embedding vector space에서 가장 확률이 높은 단어를 찾고 그 단어로부터 sampling을해서 generation하게되는데 그렇게 하지 않고 이 paper에서는 beam search라는 방법을 사용한다. beam search는 단어 하나를 달랑 만드는게 아니고 k개의 후보를 항상 유지하고 있는 방법으로. 이 paper에서는 k를 기본 20개를 사용하고있는데, 현재 지점에서 가장 그럴듯한 sentence 20개를 만들어서 맨 마지막에 그중에서 가장 그럴듯한것을 하나 선택하는 방법이다. 그렇게 안하고 그냥 후보를 1개만 유지하면 나중에 bleu수치가 2가 줄어듭니다. K개를 유지하게해서 bleu를 이만큼 늘렸다 라고 논문에서 주장하고있다.
Experiment
Evaluation Metric
Human subject score, blue, perplexity, cider, meteor, rouge, recall 을 사용하여 평가 척도를 제시함
Dataset
MS COCO를 포함하여 Pascal, Flickr 등 여러 Data set을 사용하였고 각각 캡션을 5개씩 달아서 사람보고 캡션을 달아달라고하여 training set을 사용. (SBU는 Flikcr에서 유저들이 올린 description이므로 noise가 심한 dataset) 또한 Pascal 데이터는 test를 위해서만 사용하였는데, 나머지 4개의 data set으로 학습을 하고 평가를 하는 식으로 사용헸다함.
Training Detail
- Training challenges: overfitting – datasets are smaller
- Solution
- Init CNN weight using pretrained model (e.g ImageNet)
- Note: word embedding vector uninitialized
- Dropout
- Ensemble
- All weights randomly initialized except for the CNN
- SGD on mini-batches
- 512 dimensional embedding
- Fixed learning rate, no momentum
