[ML] Concept Learning
in Data Science on Machine Learning
Concept 이란?
some subset of objects or events defined over a large set.
큰 집합에서 정의되는 작은 객체나 이벤트.
ex) Animal 중 Bird 라는 concept.
Learning
inducing general functions from specific training examples 구체적인 훈련 사례에서 일반적인 기능을 유도하는것
Concept Learning (Category Learning)
학습데이터로부터 기냐? 아니냐?를 판단할수 있는 정의를 얻는것
Inductive learning hypothesis
귀납적 학습 가설. 충분한 데이터를 가지고 학습하면 모르는 데이터도 맞출 수 있다.
general-to-specific ordering
더 적은 제약조건을 가지는 가설을 더 general 하다고 표현하고
더 많은 제약조건을 가지는 가설을 더 specific 하다고 표현한다.
Find-S algorithm
most specific한 가설에서 next general 한 가설로 바꿔나가는 방법.
problem in Find-S algorithm
- 진짜 학습된건지 알 수 없음
- 가설에 입각해 여러가지 솔루션이 나올 수 있음
- noise data에 취약
version space
version space = solution space. training example(학습예제) D와 일치하는 가설 H 를 모은 공간.
the general boundary(가장 일반화된 멤버) 와 the specific boundary(가장 구체화된 멤버)를 찾으면 그 둘 사이가 version space가 된다. 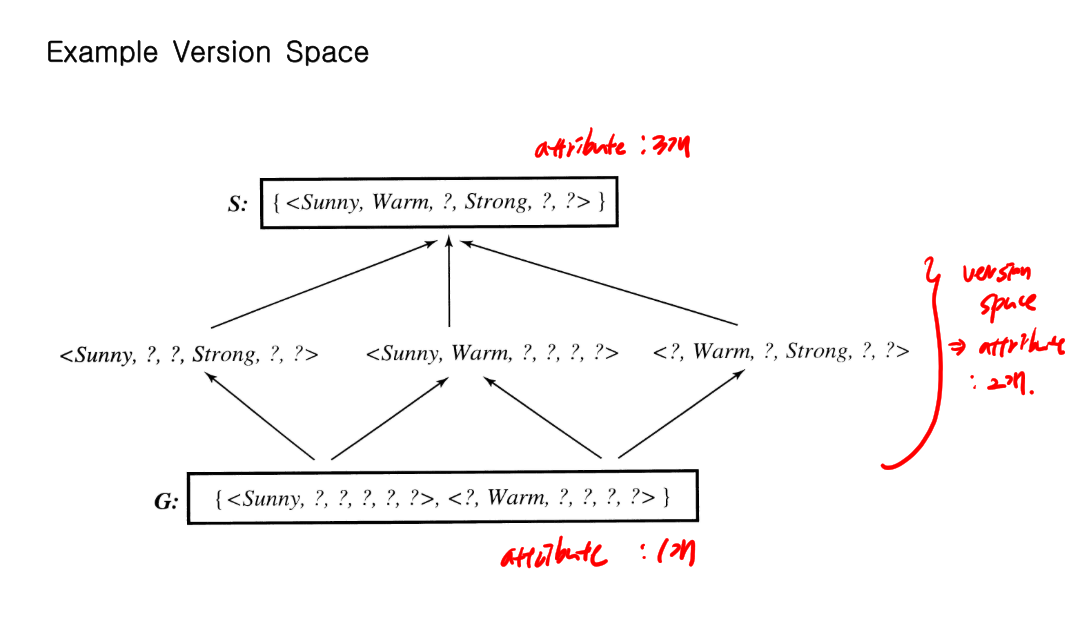
CE (Candidate Elimination) algorithm
step
step 1. general boundary, specific boundary 정의. step 2. training sample d 에 대하여 (1) d가 positive sample 이면 specific boundary update (2) d가 negative sample 이면 general boundary update
characteristic
CE algoritme은
(1) nosie data가 없다면
(2) target concept이 가설공간에 포함되어있다면
target concept을 정확히 설명하는 가설을 향해 수렴할것이다.
Inductive bias
귀납적 추론을 할 때, target space에 대해 명확히 정의하지 않으면 보이지 않는 경우에 대해서는 명확히 판단할 근거가 없음. 따라서 assumption을 제대로 만들어 넣어야 학습을 빨리할 수 있고 더 의미있는 결과를 얻을 수 있음. Inductive bias는 target concept과 training example의 minimal set of assumption (최소한의 주장) 이다. 쉽게 말해, 임의로 모델에 가하는 제약사항같은것이다. 이 inudctive bias가 없으면 귀납적 추론을 할 때 모든 가설을 다 뒤져야하므로 적절한 inductive bias 적용이 필요하다.
