Sequence to Sequence Learning with Neural Networks
in Data Science on Paper
Sequence to Sequence Learning with Neural Networks
1. Introduction
DNN은 좋은 모델이지만 고정된 차수의 벡터로 인코딩 될 수 있는 문제에만 적용할 수 있어서 가변적인 sequence to sequence 모델에는 사용할 수 없다. 이 논문에서는 LSTM의 간단한 적용으로 일반적인 sequence to sequence 문제를 풀 수 있다는 것을 보여준다. 이 논문에서 제시하는 방법은 LSTM을 사용하여 소스 시퀀스를 벡터에 매핑 한 다음, 또 다른 LSTM을 사용하여 벡터를 타겟 시퀀스로 디코딩하는 방법이다. 당시에는 LSTM에 긴 문장을 사용한 사례가 없었는데, 저자들은 소스 문장을 거꾸로 입력하는 방식으로 단기 의존성을 도입하여 LSTM으로 긴 문장을 성공적으로 학습할 수 있었다.
2. The model
일반적인 시퀀스 학습을 위한 전략은 하나의 RNN을 사용하여 고정된 크기의 벡터에 입력 시퀀스를 매핑 한 다음 다른 RNN이있는 대상 시퀀스에 벡터를 매핑하는 것이다. 그러나 RNN을 이용하면 장기종속성 문제로 인하여 학습이 어려울 수 있다. 때문에 LSTM (Long Short-Term Memory) 모델을 사용하여 문제를 해결할 수 있다.

이 논문에서 사용된 모델의 구조는 위와 같으며, LSTM은 “A”, “B”, “C”, “EOS”의 representation을 계산한 다음 이를 사용하여 “W”, “X”, “Y”, “Z”, “EOS”의 확률을 계산한다.
이 논문의 모델 특징은 다음과 같다. 1) 입력 시퀀스를 위한 LSTM, 출력 시퀀스를 위한 LSTM. 두 가지 다른 LSTM을 사용했다. 2) Deep LSTM이 shallow LSTM보다 성능이 좋기 때문에 4 layer LSTM을 사용했다 3) 입력 문장의 단어 순서를 거꾸로 하여 LSTM의 성능을 크게 향상시켰다.
3. Experiments
저자들은 2가지 방법으로 위 모델을 WMT’14 English to French MT task에 적용하였다.
3.1 Dataset details
WMT’14 English to French dataset를 사용하였고 348M개 프랑스어 단어와 304M개 영어 단어로 구성된 12M개 문장의 하위 집합으로 training하였다.
3.2 Decoding and Rescoring
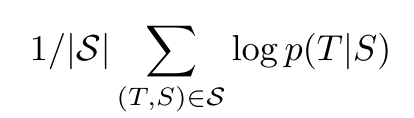
원본 문장 S에 대해 올바른 번역 T의 로그 확률을 최대화하도록 training하였다.
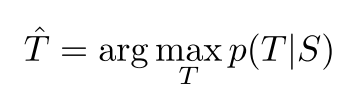
훈련이 완료되면 LSTM으로 가장 가능성이 높은 번역본을 찾아 변환한다 simple left-to-right beam search decoder를 사용하여 가장 좋은 번역결과를 탐색한다.
3.3 Reversing the Source Sentences
소스문장을 역전시켜 입력하면 LSTM이 훨씬 더 잘 학습한다는 것을 발견했다. 확실하지는 않지만 저자들은 소스문장을 역전시키면서 데이터셋에 대해 단기 종속성이 도입되어 성능이 향상된 것으로 추측하고 있다.
3.4 Training details
1) 0.08과 0.08 사이의 균일한 분포로 LSTM의 모든 파라미터를 초기화 2) momentum없는 SGD, 고정 학습률 0.7, 배치사이즈 128, 3) exploding gradient방지를 위해 임계치 초과시 scaling적용 4) minibatch 내 문장을 대략 같은 길이로 설정
3.5 Parallelization
8GPU 사용하여 모델을 병렬화했다.
3.6 Experimental Results
WMT’14 English to French test set 사용하였을 때 제일 이전 최고 BLEU 37보다 0.5 낮은 36.5 까지 나왔다.
3.7 Performance on long sentences
표와 그림에 제시된 결과를 보면, LSTM이 긴 문장에 대해 매우 잘 학습했음을 알 수 있다. 3.8 Model Analysis 이 모델의 특징 중 하나는 vector of fixed dimensionality를 sequence of words로 변환할 수 있다는 것이다.
4. Related work
기존에도 기계번역에 RNN을 적용하는 많은 연구들이 있었고, 최근에 와서는 NNLM에 소스 언어에 대한 정보를 포함하는 방법이 연구되었다. 저자들은 기존의 CNN이나 attention mechanism 도입 연구들처럼, reversed source sentence로 훈련함으로써 그와 유사한 개선을 이룰 수 있다고 제안한다.
5. Conclusion
번역작업에서 단지 source sentence를 뒤집어 입력하는 것 만으로 크게 개선을 이루어 놀랐고, 단기 의존성 문제가 무척 중요하다는 걸 깨달았다. 이로 인해 LSTM이 긴 문장을 정확히 번역할 수 있었다. 이러한 접근 방식은 다른 sequence to sequence problems에도 잘 적용될 것이다.
1. 논문의 장점
sequence to sequence problem에 대해 machine translation으로 실험하여 알기 쉽게 접근하여 설명하고있으며 기존에 진행된 RNN을 사용한 다른 연구들과 비교하여 설명해 해당 분야에 대해 어떤 시도들이 이어져왔는지 함께 알 수 있었다. 또한 최종적으로 저자들이 무척 간단한 아이디어만으로 sequence to sequence problem분야에서 큰 성능의 개선을 이끌어 낸 점이 흥미롭다.
2. 논문의 단점
장기의존성 문제를 해결하기 위해 LSTM을 사용하는 점, shallow LSTM보다 deep LSTM이 좋아서 layer를 더 쌓았다는 점 등 source sequence를 reverse하는 아이디어 외에는 기존 연구들과 특별한 차별점이 없어 보인다.
3. 느낀 점
source sequence를 reverse하여 입력하여 단기의존성을 향상시킨다는 아이디어가 이 논문의 주요 아이디어인데 이렇듯 일견 단순하고 간단해 보이는 아이디어 하나가 딥러닝 전반의 개선을 이끌어 낼 수 있다는 점이 놀라웠다. 어떤 문제라도 본질적 원인을 찾으려 노력한다면 아주 작은 아이디어만으로도 해결할 수 있다는 것을 깨달았다.
